
The format of this series is an outline of my thought process during the development of @thehaikuza.
Poetry is hard
To write when algorithms
Are extremely dumb.
I dont want my haiku generator to be a vegetarian chef. There’s nothing wrong with always making word salad, but eventually it’ll have to learn to make fancier things. A poetic risotto would be nice from time to time.
Leaving @thehaikuza to make complete gibberish wasnt what I had intended. I envisioned my algorithm to be able to reconstruct bad haikus, but definitely not as crappy as the ones it actually made. My idea of bad had more to do with this xkcd comic:

iOS Keyboard Predictions (Source: xkcd.com/1427)
In any event, I needed to try something a little more sophisticated than shoving words into slots where they didn’t really fit.
The Lesser Known Cousin of 2 Chainz
Every time I Googled a new topic I didnt know about, five more topics were thrown on my plate. Notable keywords that popped up:
- Computational linguistics
- Neural networks
- Sentiment classification
- Bayesian inference
- Tree kernels for semantic role labeling
- Markov chains
By no means am I suggesting that I understood all of those search terms after reading about them. In fact, I still don’t and am constantly trying to wrap my head around those polysyllabic words. (Fun fact: anything above three syllables starts to scare most people.) The takeaway is the last item on the list, which coincidentally is the one I did manage to (somewhat) understand: the Markov chain.
A Primer for Markov Chains
In technical terms, a Markov chain is any random process that undergoes transitions from one state to another. It’s also a memoryless process, meaning that it only cares about its current state and not the states it has previously occupied.
In less technical terms, a Markov chain is like your tokens position during a game of Monopoly. The next property that your token lands on is random (ie. its a random state transition), and every dice roll is independent of the previous roll (ie. its a memoryless process). Probability determines what the next dice roll is: theres a higher chance of rolling a 7 since there are 6 possible combinations (6/36 = 16.7% probability), whereas theres only one way to roll a 2 or 12 (1/36 = 2.8% probability).
The marvelous aspect of Markov chains is that they can work with any item, not just numbers! Lets say you wanted to form sentences using Markov chains. Given a corpus of phrases (like the entire works of Shakespeare), a flowchart like the one below can be formed and used to create new phrases. Interestingly enough, this is the basis of prediction engines used on smartphone keyboards! It will learn from your phrasing habits and try to guess what your next word will be, based on how frequently youve typed similar words or phrases (just like the above xkcd comic).
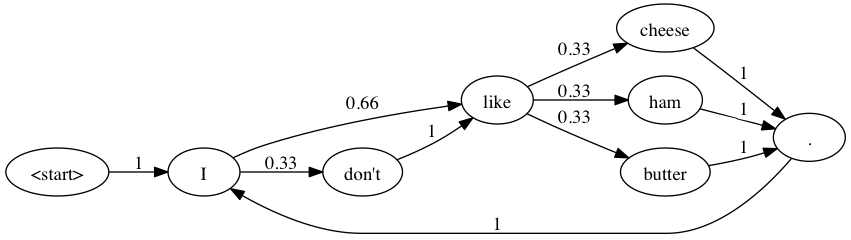
Visualization of words forming a Markov chain. (Source: Andrew Cholakian's Blog)
Harnessing its Raw, Indisputable Power
Using Markov chains would allow me to use song lyrics as a training ground for creating alternate phrases. This would consequently form a probability-based flowchart like the one above, allowing me to generate new sentences by walking through each word state and letting probability determine my next word.
To understand how to turn this into a programmable scenario, let’s take a look at an example. Given a phrase like:
Mo butter, mo better, mo slipperier
A Markov chain algorithm will take triplets of the phrase, use the first two words as the dictionary word, and the third word as the definition. If you’re familiar with using dictionaries in Python, the former is known as keys and the latter as values. This would result in the above phrase being translated to:
('mo', 'butter') : ['mo']
('butter', 'mo') : ['better']
('mo', 'better') : ['mo']
('better', 'mo') : ['slipperier']
Okay, but this isn’t very captivating because there’s a 1:1 ratio of keys to values, which means that there will never be any mixing and matching of words since the probability of the next word is always 1. Alternatively, if we have a sentence such as:
Living in a land of butter is like living in a paradise with flying unicorns
Then the resulting dictionary will look like:
('Living', 'in') : ['a']
('in', 'a') : ['land', 'paradise']
('a', 'land') : ['of']
('land', 'of') : ['butter']
('of', 'butter') : ['is']
('butter', 'is') : ['like']
('is', 'like') : ['living']
('like', 'living') : ['in']
('living', 'in') : ['a']
('a', 'paradise') : ['with']
('paradise', 'with') : ['flying']
('with', 'flying') : ['unicorns']
The interesting part of this phrase (other than the wildly imaginative scenario) is the second line item, where the key (in, a) has two possible values, either land or paradise. So if I’m wandering around a word-based flowchart and come across the pair of words in a, my next word can either be land or paradise. Now, this was just for a 15 word phrase, so imagine the magnitude of choices if lyrics for an entire song was used (where more repetitions are prevalent), or all lyrics from an artists full discography, or even a body of text with a +1,000,000 word count meant for this purpose! More phrases and more words result in more possible combinations, which is excellent news for attempting to create pseudo-random sentences.
The code below for the Markov chain algorithm was adapted from Agiliqs Blog:
import random
class Markov(object):
def __init__(self, string):
self.cache = {}
self.words = string
self.word_size = len(self.words)
self.database()
print self.cache
def triples(self):
""" Generates triples from the given data string.
"""
if len(self.words) == 3:
return
for i in range(len(self.words) - 2):
yield (self.words[i], self.words[i+1], self.words[i+2])
def database(self):
for w1, w2, w3 in self.triples():
key = (w1, w2)
if key in self.cache:
self.cache[key].append(w3)
else:
self.cache[key] = [w3]
def generate_markov_text(self, size=25):
seed = random.randint(0, self.word_size-3)
seed_word, next_word = self.words[seed], self.words[seed+1]
w1, w2 = seed_word, next_word
gen_words = []
for i in xrange(size):
gen_words.append(w1)
w1, w2 = w2, random.choice(self.cache[(w1, w2)])
gen_words.append(w2)
return ' '.join(gen_words)
Teaching Markov the Art of Haikus
Time to make some progress in making some beautifully robotic poetry! The plan for @thehaikuza V0.2 is to create a Markov chain dictionary using song lyrics and create randomized phrases from the resulting keys and values. Although this implementation still doesn’t involve a proper grammar model, it’s an improvement from the previous method because of its more structured approach. By simply mixing and matching phrases that once made sense before, there’s a much higher probability that the resulting phrase will also make some level of sense.
The success rate should now go from laughable to respectfully laughable! Progress is progress.
Check out the full repo on Github!